Simulation
Statistical Distributions
Recall from your statistics classes…
A random variable is a value we don’t know until we observe an instance.
- Coin flip: could be heads (0) or tails (1)
- Person’s height: could be anything from 0 feet to 10 feet.
- Annual income of a US worker: could be anything from $0 to $1.6 billion
The distribution of a random variable tells us its possible values and how likely they are.
- Coin flip: 50% chance of heads and tails.
- Heights follow a bell curve centered at 5 foot 7.
- Most American workers make under $100,000.

Statistical Distributions with Names!
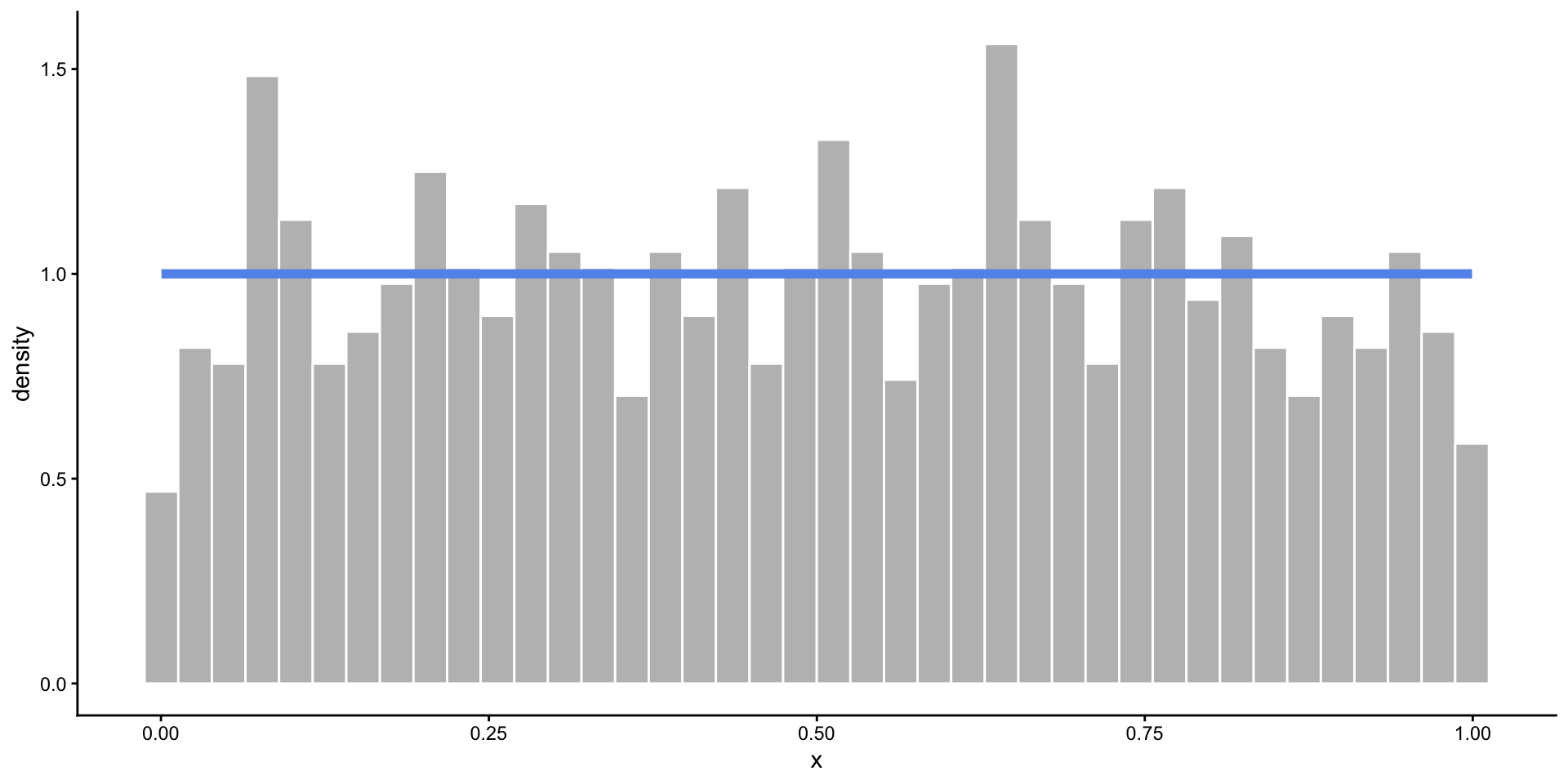
Uniform Distribution
- When you know the range of values, but not much else.
- All values in the range are equally likely to occur.
- Defined by minimum and maximum values: \(Unif(a, b)\)
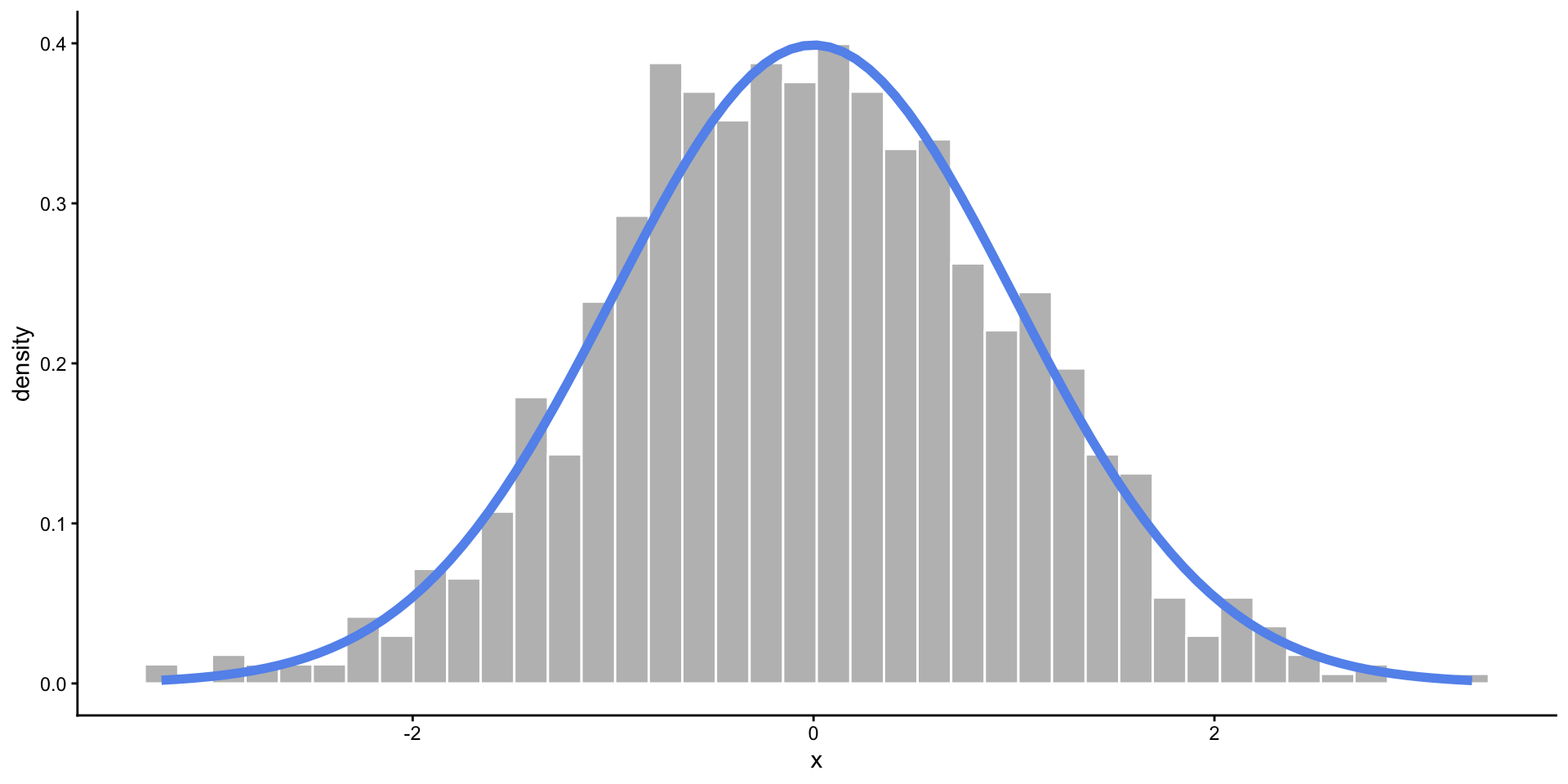
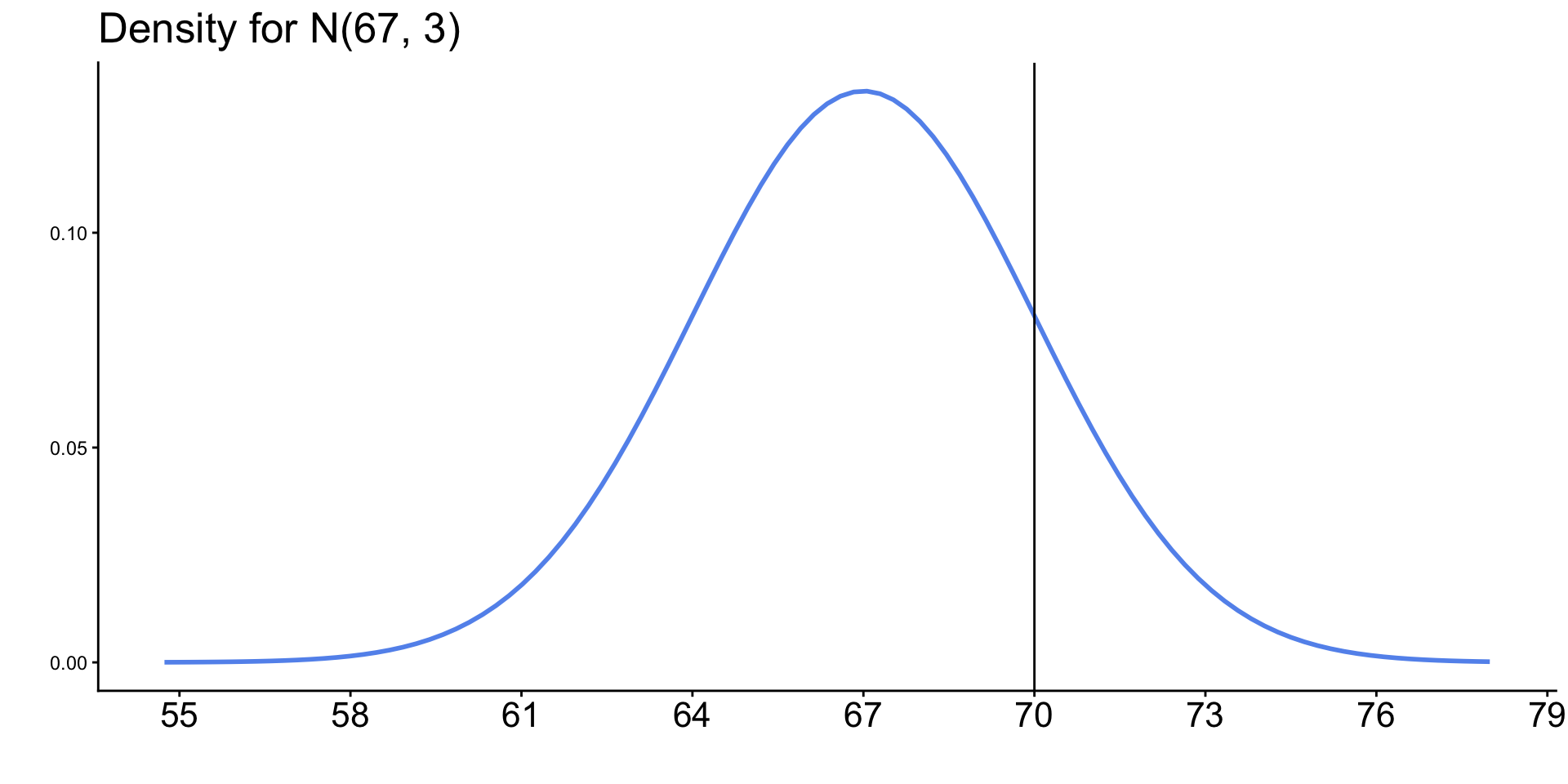
Normal Distribution
- When you expect values to fall near the center.
- Frequency of values follows a bell shaped curve.
- Defined by mean and standard deviation (or variance): \(N(\mu, \sigma^2)\)
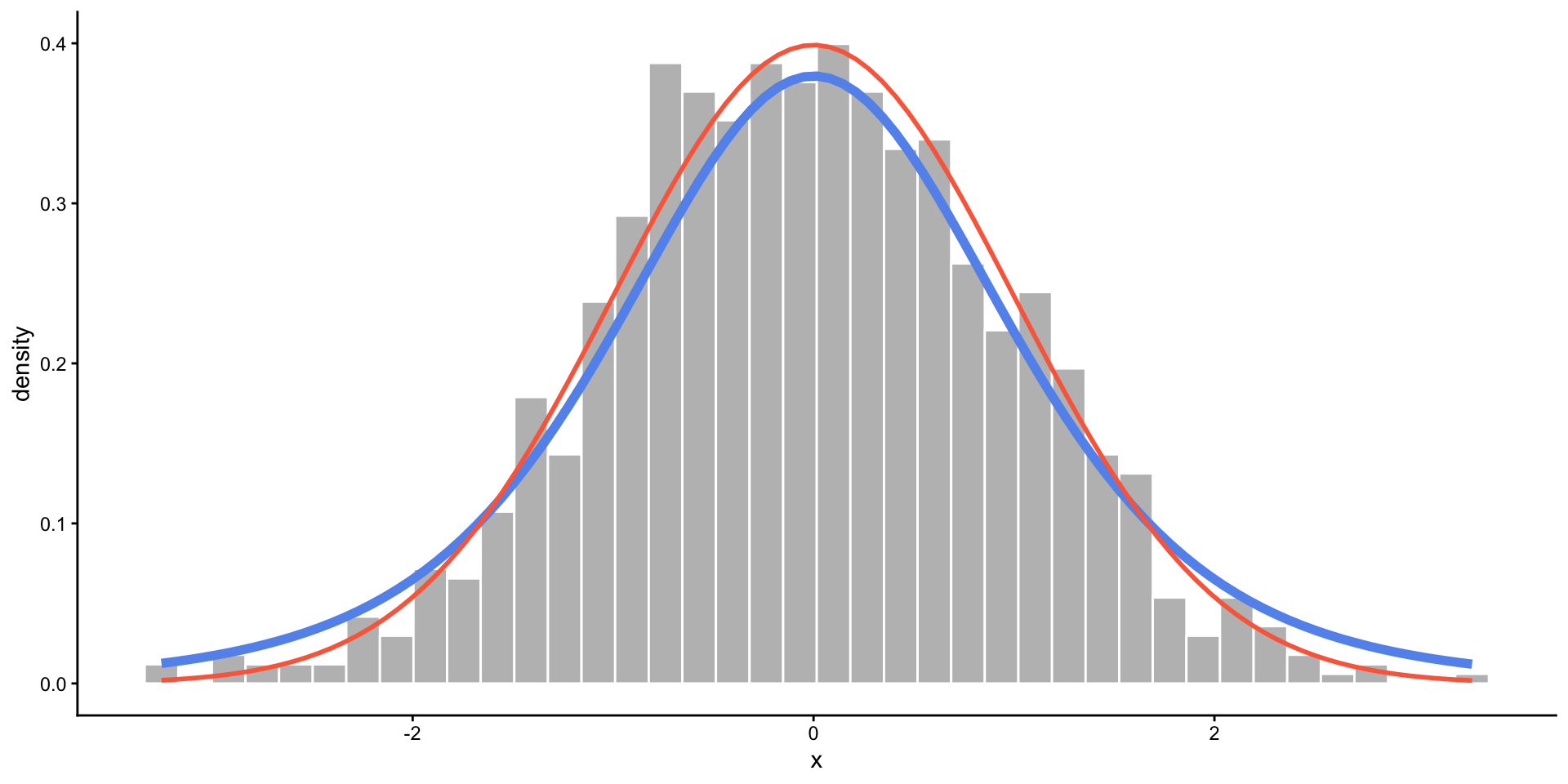
t-Distribution
- A slightly wider bell curve.
- Basically used in the same context as the normal distribution, but more common with real data (when the standard deviation is unknown).
- Defined by degrees of freedom: \(t(df)\)
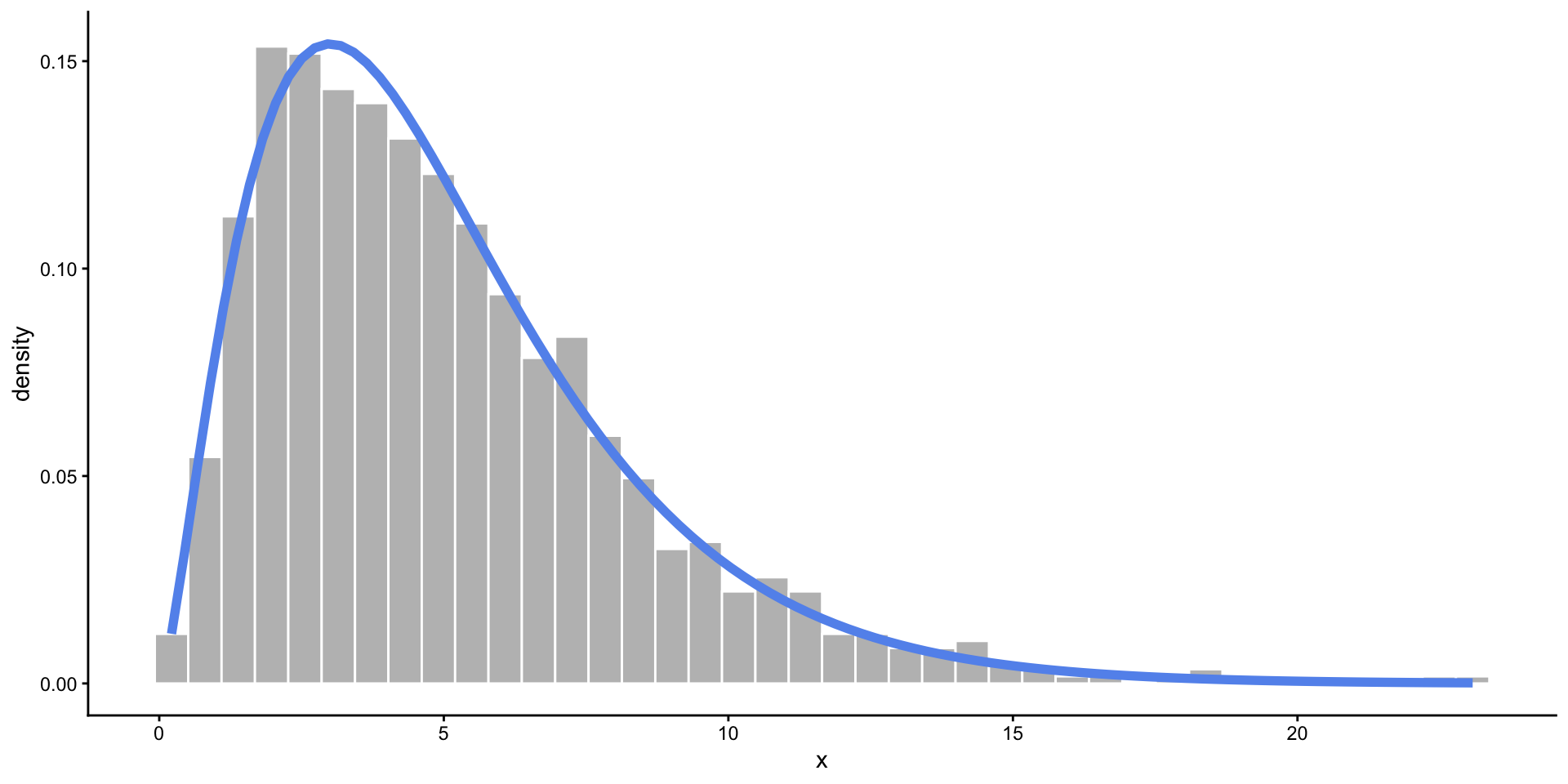
Chi-Square Distribution
- Somewhat skewed, and only allows values above zero.
- Commonly used in statistical testing.
- Defined by degrees of freedom: \(\chi^2_{df}\)
Binomial Distribution
- There are two possible outcomes, and you are counting how many times one of the outcomes (“success”) occurred out of a fixed number of trials.
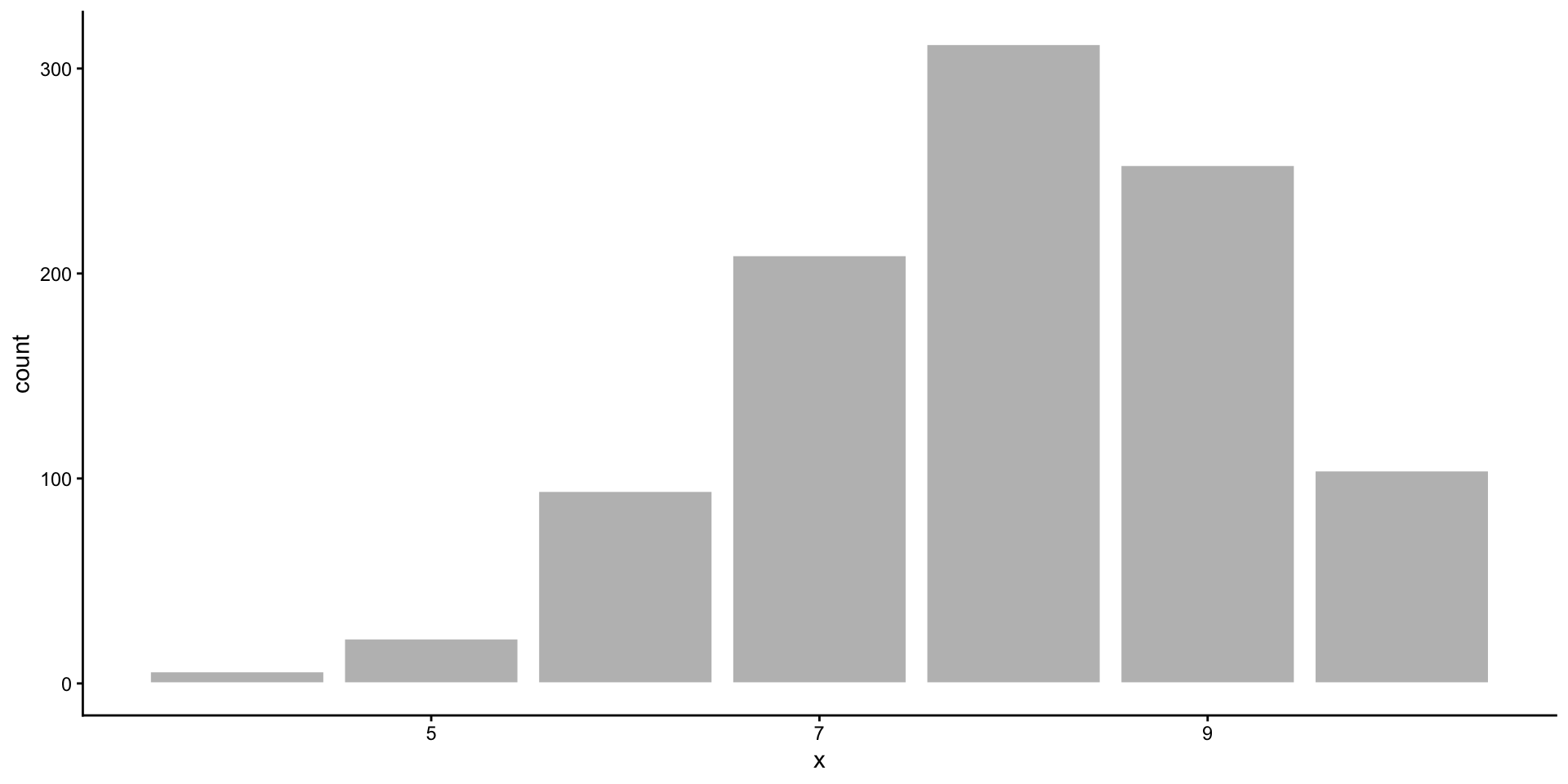
- Takes discrete values from 0 to the number of trials.
- Defined by the number of trials (\(n\)) and the probability of success (\(p\)): \(Binom(n, p)\)
Distribution Functions in R
- There are four functions for each of these distributions to accomplish different tasks!
- The parameters that define each distribution are arguments
- e.g.
minandmaxfor the Uniform distribution
- e.g.
- Documentation can be found for each distribution

Distribution Functions in R
r is for random sampling.
- Generate
nrandom values from a distribution. - We use this to simulate data (create pretend observations).
p is for probability.
- Compute the chances of observing a value less than
x: \(P(X < x)\) - We use this for calculating p-values.
q is for quantile.
- Given a probability
p, compute \(x\) such that \(P(X < x) = p\). - The
qfunctions are “backwards” of thepfunctions. - We use this for calculating critical values (z*).
d is for density.
- Compute the height of a distribution curve at a given
x. - For discrete dist: probability of getting exactly
x. - For continuous dist: usually meaningless.
- Mostly useful for plotting the distribution!
Probability of exactly 12 heads in 20 coin tosses, with a 70% chance of tails?
Empirical vs. Theoretical Distributions
Empirical: the observed data.
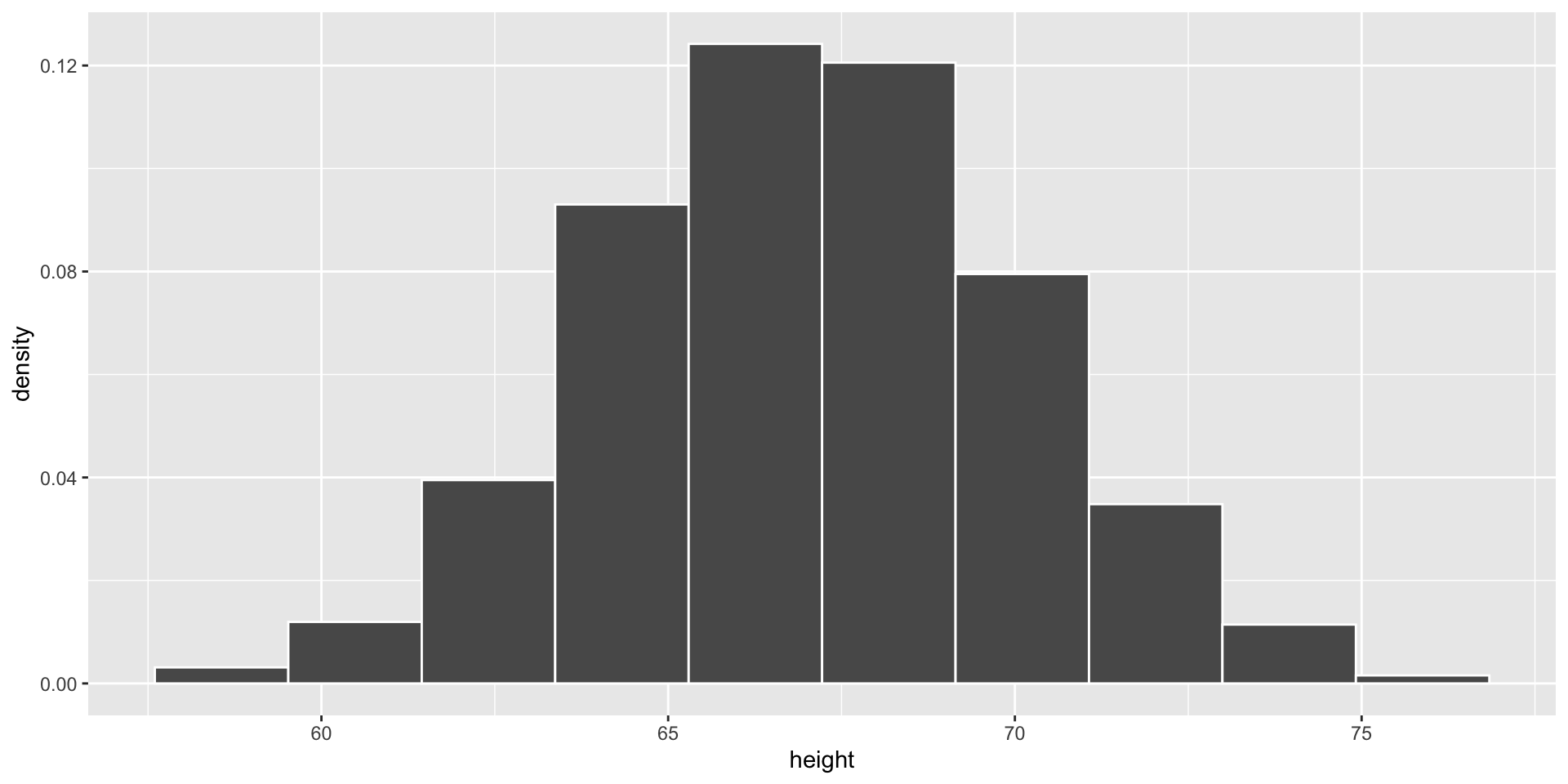
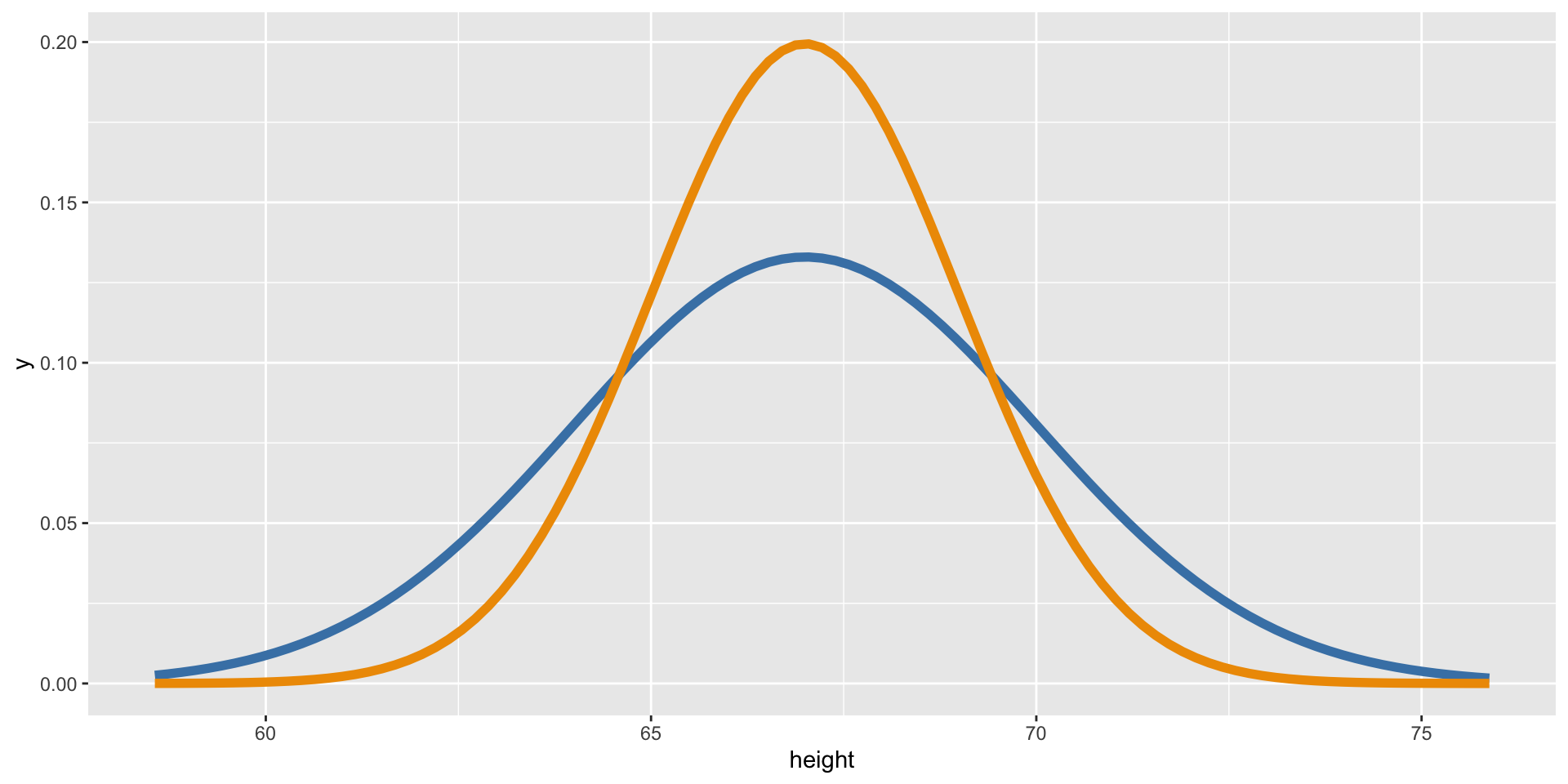
Plotting Both Distributions
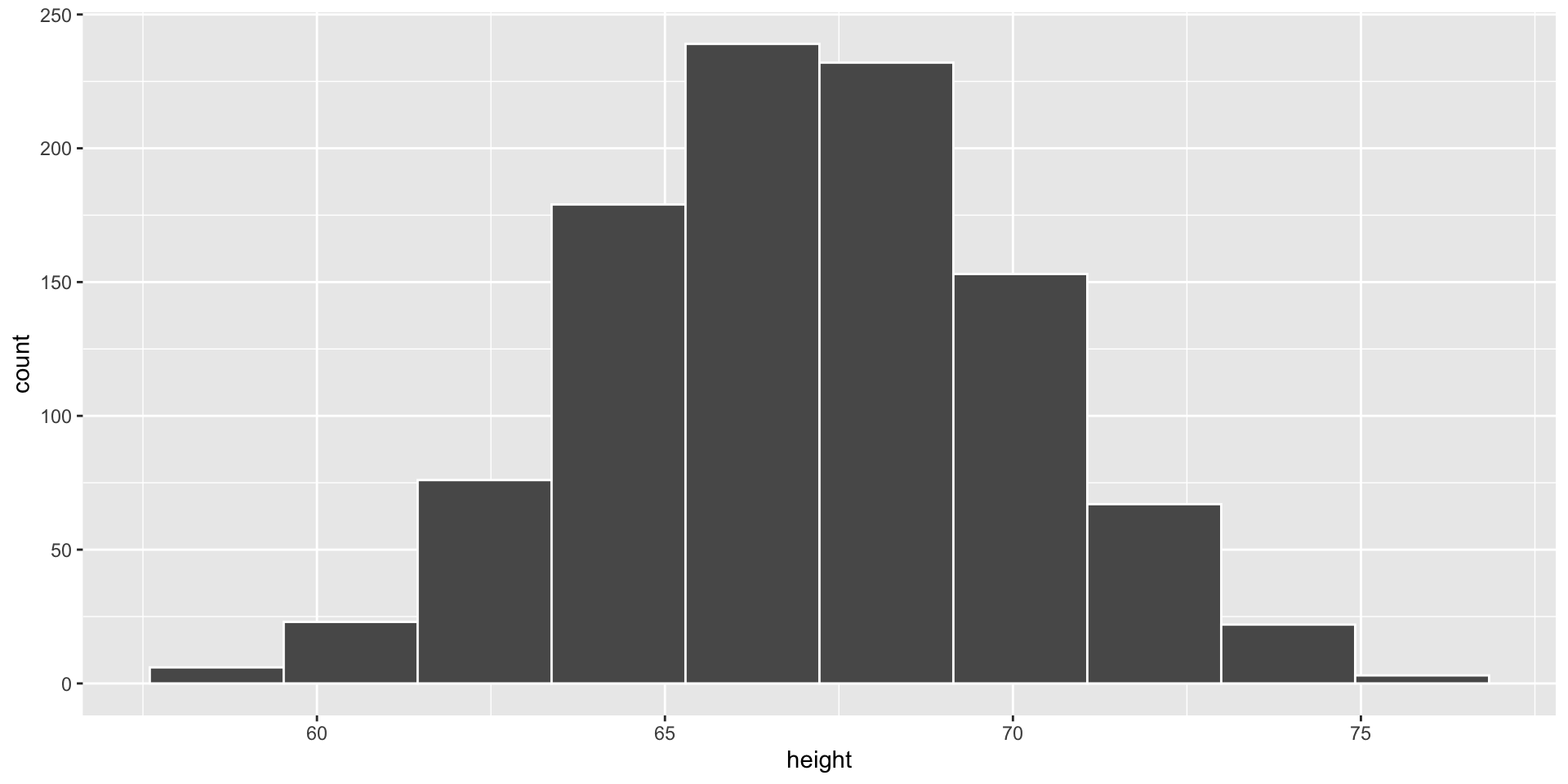
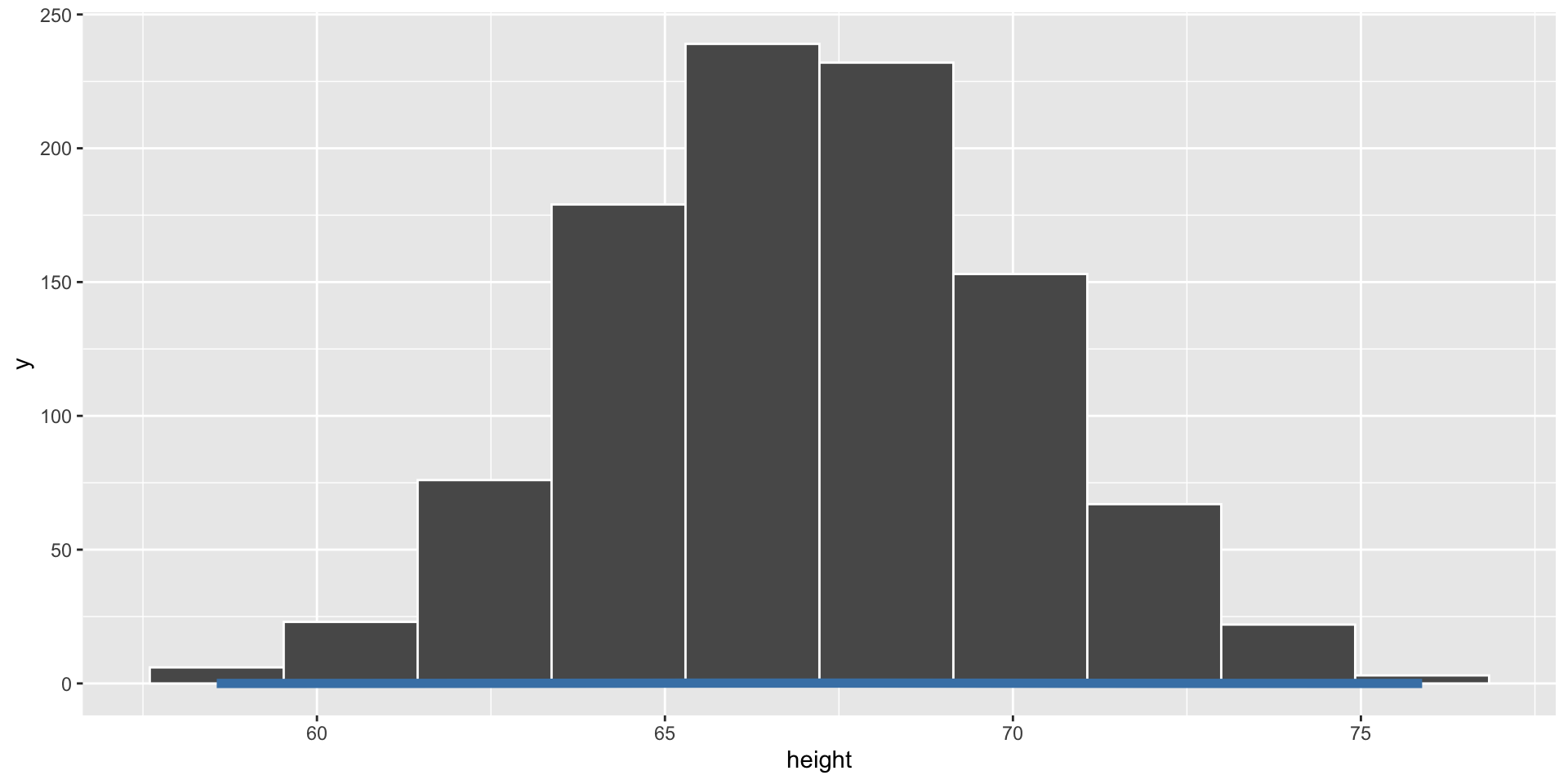
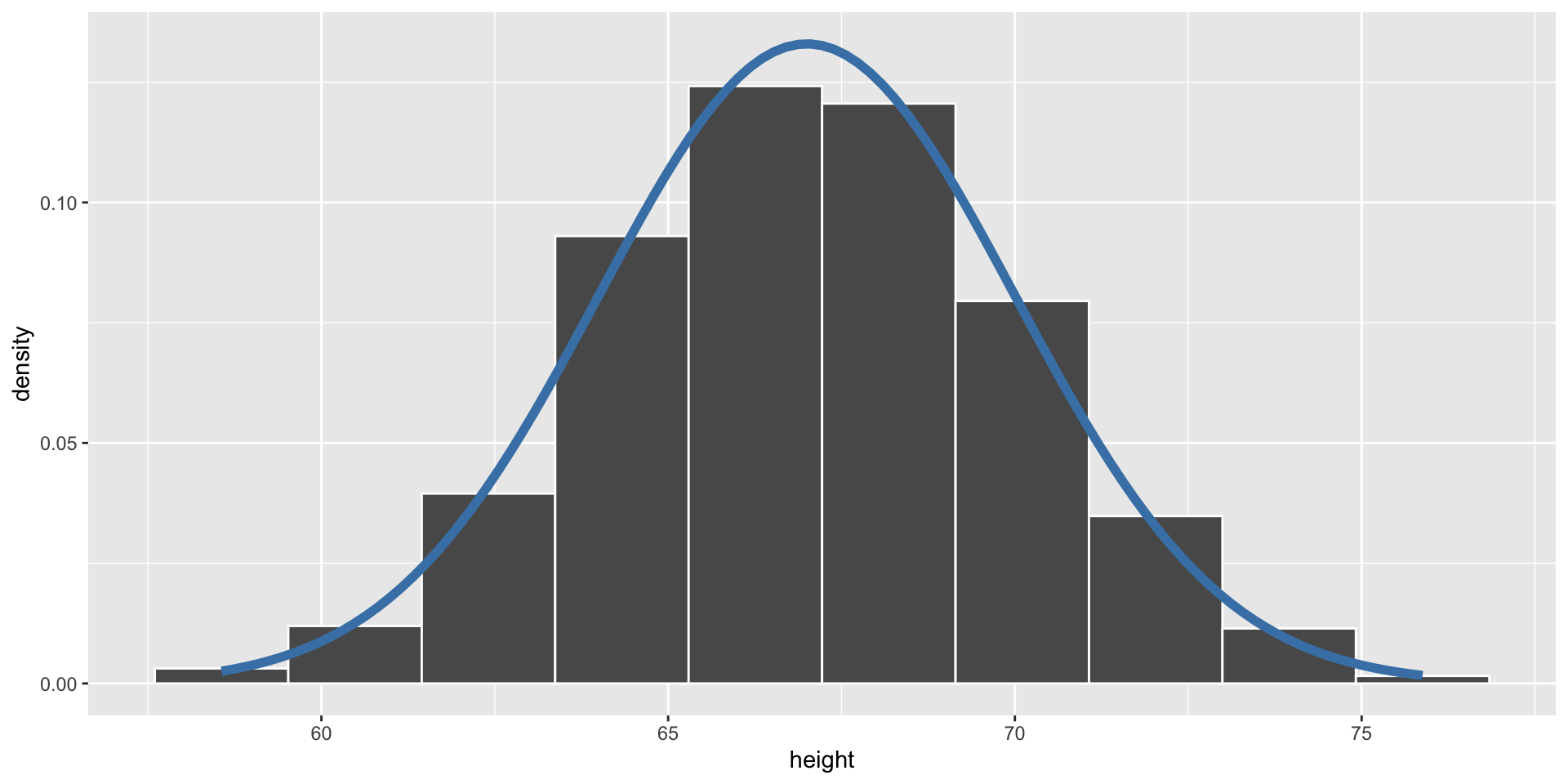
Simulate a Dataset
| names | height | age | measure | supports_measure_A |
|---|---|---|---|---|
| Elbridge Kautzer | 67.43632 | 66.29460 | 1 | yes |
| Brandon King | 64.99480 | 61.53720 | 0 | no |
| Phyllis Thompson | 68.09035 | 53.83715 | 1 | yes |
| Humberto Corwin | 67.45541 | 33.87560 | 1 | yes |
| Theresia Koelpin | 71.37196 | 16.12199 | 1 | yes |
| Hayden O'Reilly-Johns | 66.17853 | 36.96293 | 0 | no |
Check to see the ages look uniformly distributed.
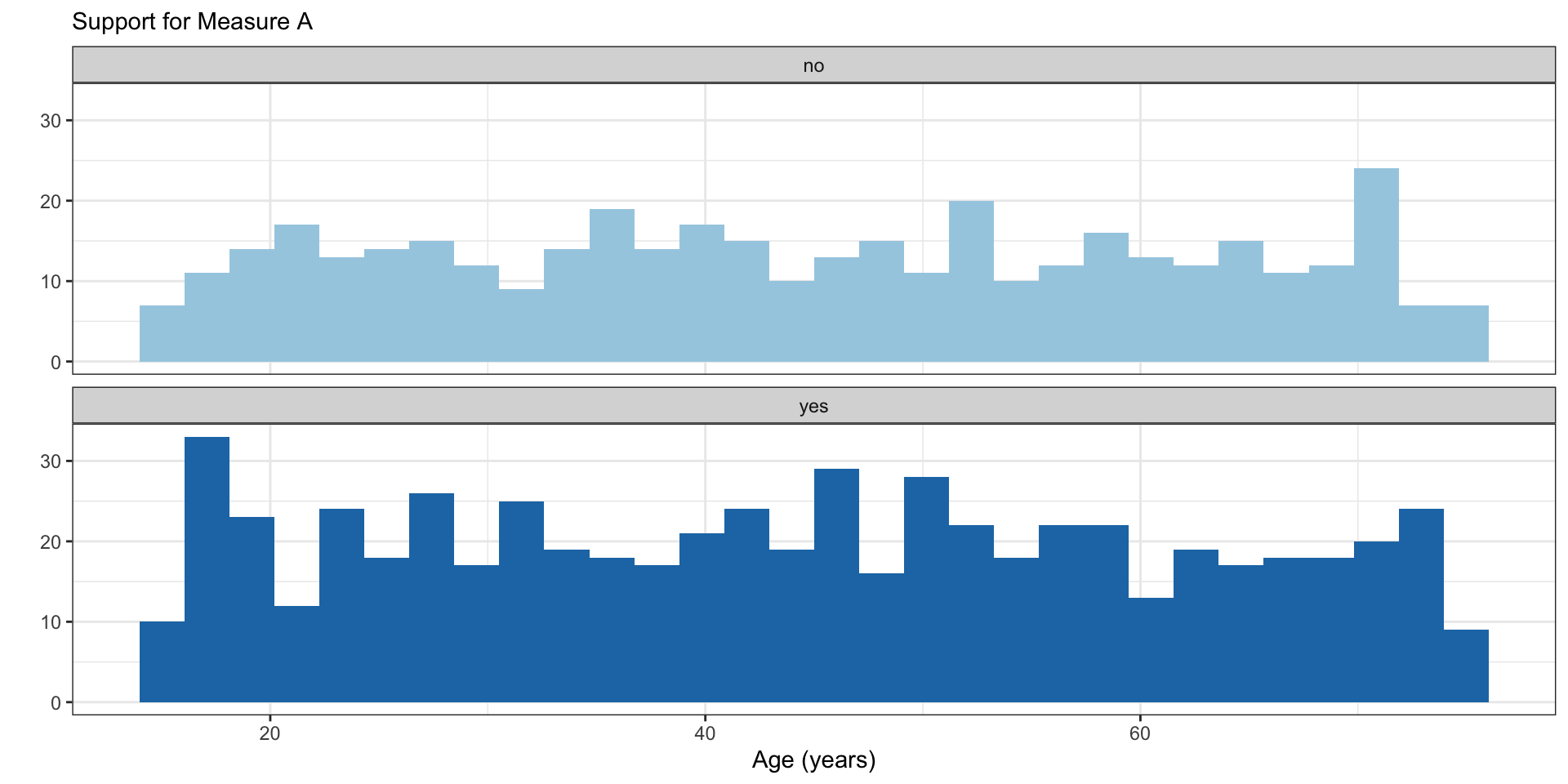
The pmap() Family
These functions take in a list of vectors and a function.
- The function must accept a number of arguments equal to the length of the list,
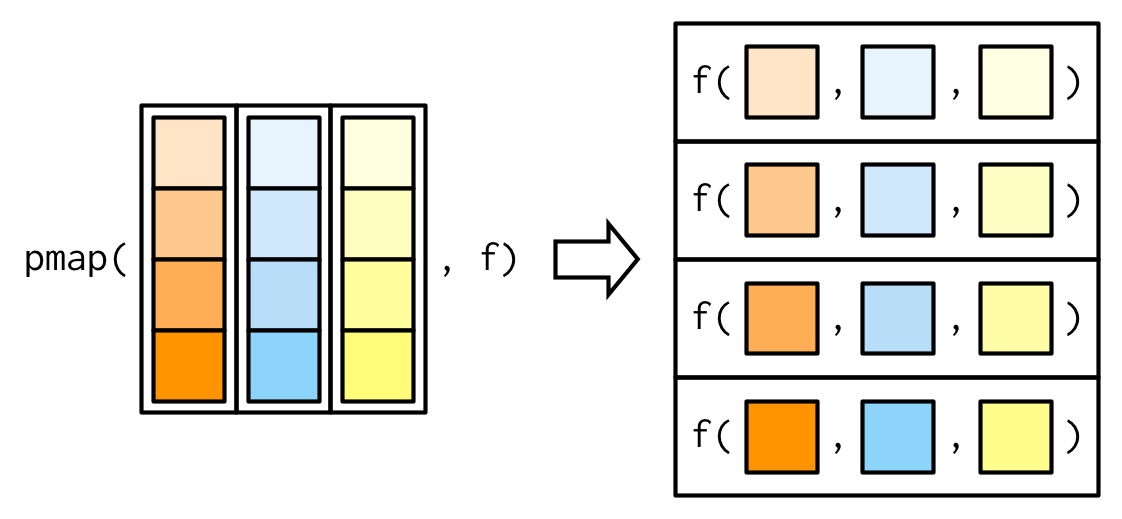
Simulate Multiple Datasets - Step 5
Plot the samples simulated from each population.
Code
fake_ht_data |>
mutate(across(.cols = mean_ht:std_ht,
.fns = ~as.character(.x)),
mean_ht = fct_recode(mean_ht,
`Mean = 60` = "60",
`Mean = 66` = "66",
`Mean = 72` = "72",
`Mean = 78` = "78"),
std_ht = fct_recode(std_ht,
`Std = 3` = "3",
`Std = 6` = "6")
) |>
ggplot(mapping = aes(x = ht)) +
geom_histogram(color = "white") +
facet_grid(std_ht ~ mean_ht) +
labs(x = "Height (in)",
y = "",
subtitle = "Frequency of Observations",
title = "Simulated Heights from Eight Different Populations")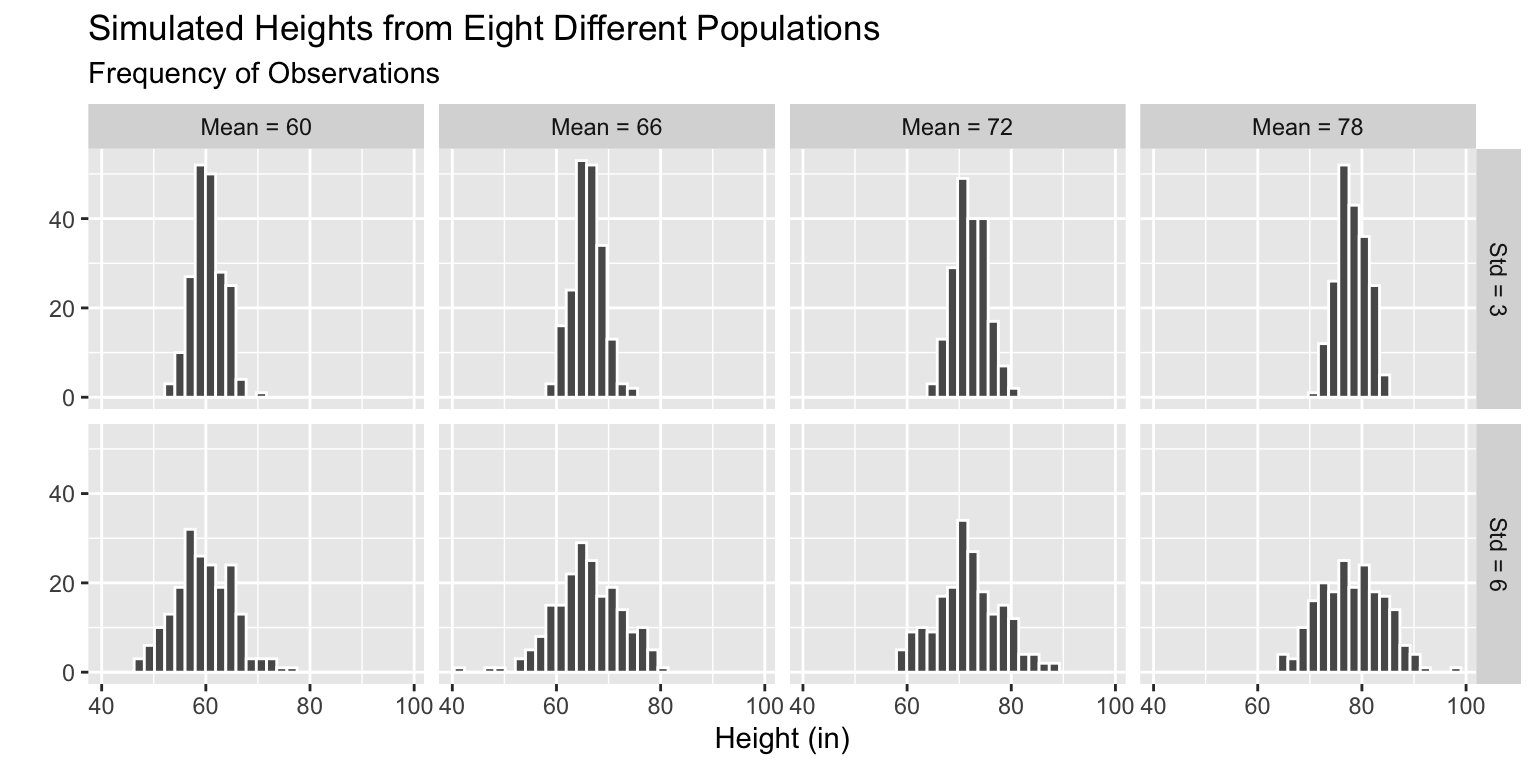
Remember the Data Science Process
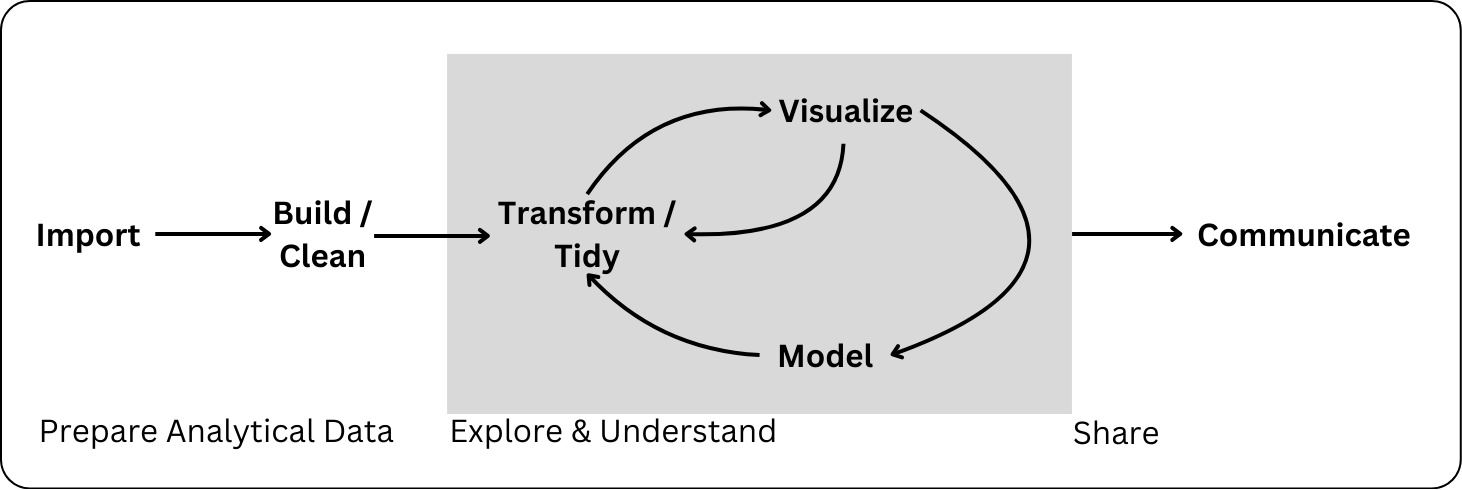
Communicating about your analysis and findings is a key element of statistical computing.
PA 8.2: Instrument Con
Work with statistical distributions and iterating random processes to determine if an instrument salesman is lying.

–>
Lab 8: Data Frame Functions and Simulation
