library(tidyverse)
library(broom)Lab 9: Regression Exploration
What are standardized tests measuring?
There have long been critiques of standardized tests as a true measurement of student learning and “intelligence.” Are standardized tests really measuring learning or are they catching other information about students like their class, circumstances at home, wealth of the school district, etc?? If a school has a higher average SAT Math score, does this indicate that the students and teachers at that score “better” than schools with lower SAT Math scores or are other factors at play?
We have data on 332 high schools in Massachusetts in 2017 (MA_schools.csv). The original source of the data are Massachusetts Department of Education reports and is provided in ModernDive.
You can find the data dictionary for the data through ModernDive.
I am interested in the relationship between the average SAT math score at schools in Massachusetts and the percent of the student body that are considered “economically disadvantaged.”
1. Create a well-formatted scatterplot of average_sat_math versus perc_disadvan along with the linear regression line. How would you describe the relationship between these two variables?
Tip
Which variable is the explanatory variable and which is the response variable?? Pay attention to which should be plotted on the y-axis versus the x-axis.
# Q1 code2. Fit a simple linear regression model of average SAT math score on percent economically disadvantaged. Provide nicely-formatted table of the estimated model coefficients including some indication of variability (standard error or confidence interval) and a p-value.
Tip
To make the table, you can either use a function from the broom package along with some of the table formatting techniques with kableExtra and gt we learned last week OR a function from the gtsummary package that we saw in class.
# Q2 code3. Conduct model diagnostics to check that the conditions for linear regression that we discussed in class are met (L.I.N.E.). You may need multiple plots or output to check all diagnostics. You should be using techniques that we learned in class - not base R functions.
Tip
For assessing the normality of the residuals, theory tells us that the random errors are normally distributed with mean 0 and standard deviation \(\sigma\) (\(N(0,\sigma)\)). We don’t know the value of \(\sigma\), but can try to estimate it with the standard deviation of the residuals themselves. See the slides for helpful code to do this!
# Q3 code4. Briefly discuss (2-3 sentences) what you learned about the relationship between average math ACT scores and socioeconomic status in Massachusetts schools from this analysis.
NoteLearn more
If you are interested in discussions of the use, history, and issues with standardized testing I would highly recommend the Radiolab series G.
Simulation-based Inference
The p-values that are provided in regression output for the slope coefficient is testing the hypotheses:
\(H_0: \beta_1 = 0\) vs. \(H_A: \beta_1 \neq 0\)
As a reminder, the assumed linear model is \(Y = \beta_0 + \beta_1 X + \varepsilon\), so \(\beta_1 = 0\) is equivalent to saying there is no relationship between the explanatory and response variables.
The p-values provided in regression output in most software are based on a theory-based null distribution, which rely on the assumptions that we discussed in class.
Another approach to generating a null distribution to test the null hypotheses above is through simulation! Assuming the null hypothesis is true, that there is no relationship between the explanatory and response variables, then the % of economically disadvantaged students for each school should have no impact on the mean Math ACT score.
To emulate this null hypothesis of no reationsip in simulation, we permute the values of the explanatory variable between all schools, while leaving the response values the same. Here is an illustration with 10 observations from the data:
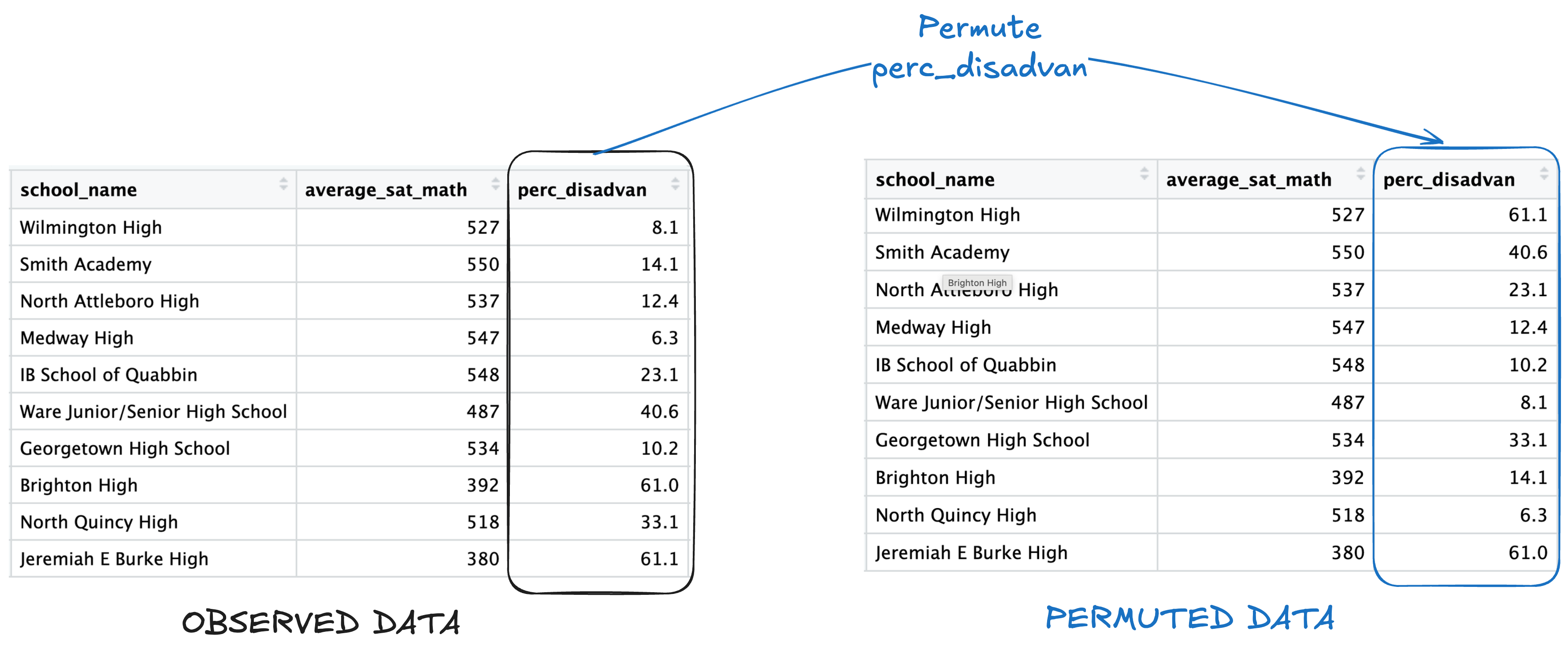
Let’s generate a simulation-based null distribution and see if it aligns with the theory-based test!
5. Fill in the function code below to conduct one simulation, generating a t-statistic for the slope coefficient, assuming the null hypothesis is true. This function should:
- randomly permute/shuffle the values of the explanatory variable among the observations (⚠️ edit the variable - don’t create a new variable)
- fit a linear regression model of the response variable on the explanatory variable
- return the value of the t-statistic for the slope coefficient.
Important
I have filled in some of this code for you! You shouldn’t have to edit Step 2.
Particularly, need another function we haven’t learned yet to use bare variable names as a formula – substitute().
If the function is called like so:
perm_slr(dat = penguins,
resp = bill_len,
exp = flipper_len)Then the code in Step 2 will fit the model bill_len ~ flipper_len.
perm_slr <- function(dat, resp, exp){
# Step 1: create a new dataframe with the values of the explanatory
# variable randomly permuted between the observations
perm_dat <-
# Step 2: fit a regression model with the permuted data created in step 1
mymod <- lm(substitute(resp ~ exp), data = perm_dat)
# Step 3: return the t-statistic for the estimated slope coefficient
# from the model
}Make sure that your function works by running this code! It should just output a single number.
perm_slr(dat = MA_schools,
resp = average_sat_math,
exp = perc_disadvan)Now let’s generate a null distribution for the t-statistic! I set up code for you to run 1,000 iterations of the simulation.
set.seed(331)
perm_results <- map_dbl(.x = 1:1000,
.f = ~ perm_slr(dat = MA_schools,
resp = average_sat_math,
exp = perc_disadvan))6. Plot the simulation results! Using ggplot, create a histogram of the simulated t-statistics. Theory tells us that the distribution of those t-statistics should follow a \(t\) distribution with \(n-1\) degrees of freedom, where \(n\) is the number of observations in the data. Add the theoretical density curve for a \(t\) distribution with \(n-1\) degrees of freedom. Does it look like the theoretical curve matches the simulated curve? Is the observed t-statistic for the actual data (Question 2) unusual based on this null distribution?
Tip
You will need to convert the perm_result vector into a dataframe or tibble before passing it into ggplot()!
# Q6 codeYou just implemented simluation-based inference for simple linear regression like in the Rossman-Chance applets 🥳!
Simulating Coverage
Many students struggle with the definition of a confidence interval when first learning the concept. The interpretation that a lot of textbooks include is something like “if we were to repeat the study many many times, 95% of the confidence intervals would contain the true population parameter.”
We are going to implement a simulation that illustrates this statistical concept using confidence intervals for the slope parameter in a linear regression model.
Let’s break it down into a couple of steps.
As a reminder, the typical population model that we assume for a linear regression is:
\[Y = \beta_0 + \beta_1 X + \varepsilon\] Where \(\beta_0\) and \(\beta_1\) are the population intercept and slope parameters and and \(\varepsilon \sim N(0, \sigma^2)\) is random noise that is normally distributed with mean 0 and variance \(\sigma^2\).
We will design a simulation that uses this “data generating model.”
7. Fill in the code below to generate a synthetic dataset with 100 observations. We will assume that the explanatory variable \(X\) is uniformly distributed from 0 to 1 and that \(\sigma^2\) = 1. The synthetic data should be a dataframe with 100 rows and two columns: x and y.
# define slope and intercept parameters
intercept = 2
slope = 1
# generate x vector
# generate noise `ep` vector
# generate outcome from population model
y = intercept + x*slope + ep
# create an "observed data" dataframe or tibble with only the x and y vectors8. Fit a simple linear regression model of the outcome y on x. Use tidy() from the broom package to extract a dataframe from the lm() output that includes the slope estimate and the lower and upper bounds for a a 95% confidence interval for the slope estimate. The output of this code should be a dataframe/tibble with one row three columns: estimate, conf.low and conf.high
# Q8 code9. Check whether the true population slope is inside of the estimated 95% confidence interval for that simulated dataset. Specifically, add a variable called cover to the dataframe of estimates you created in the last question (Q5) that is 1 if the population slope is in the interval and 0 if not.
Tip
As a reminder, we set slope = 1 in the data generation (Q4) so the true population slope is \(\beta_1 = 1\).
# Q9 code10. Now put this all together into a function called mycifun! Run the check provided to ensure that it works correctly
The function should have three required arguments:
beta0,beta1, andn(the number of observations in the simulated data).The function should complete the steps in Q7-9 given these arguments:
- generate one synthetic dataset based on the data generating model as above
- fit a linear regression model
- check that the population slope is contained in the estimated 95% confidence interval for the sample slope
The output of the function should be a dataframe/tibble with one row and four columns: the slope estimate, lower bound of the CI, upper bound of the CI, and whether the population slope is within the CI.
# Q10 codemycifun(beta0 = 1, beta1 = 2, n = 1000)11a. Now run this simulation 1,000 times using map_dfr() and the function you wrote (mycifun()). Generate data with \(\beta_0 = 3\), \(\beta_1 = .5\) and \(n = 100\). Make sure to add a line of code to make your simulation reproducible every time you run it.
ci_dat <- map_dfr(.x = ,
.f =
)Error in `map_dfr()`:
! argument ".f" is missing, with no default11b. What does one row in the resulting ci_dat represent?
11c. What is your simulated coverage rate? In otherwords, for what proportion of the iterations was the population slope within the estimated 95% confidence interval? Write your answer as a sentence in Markdown using inline code!
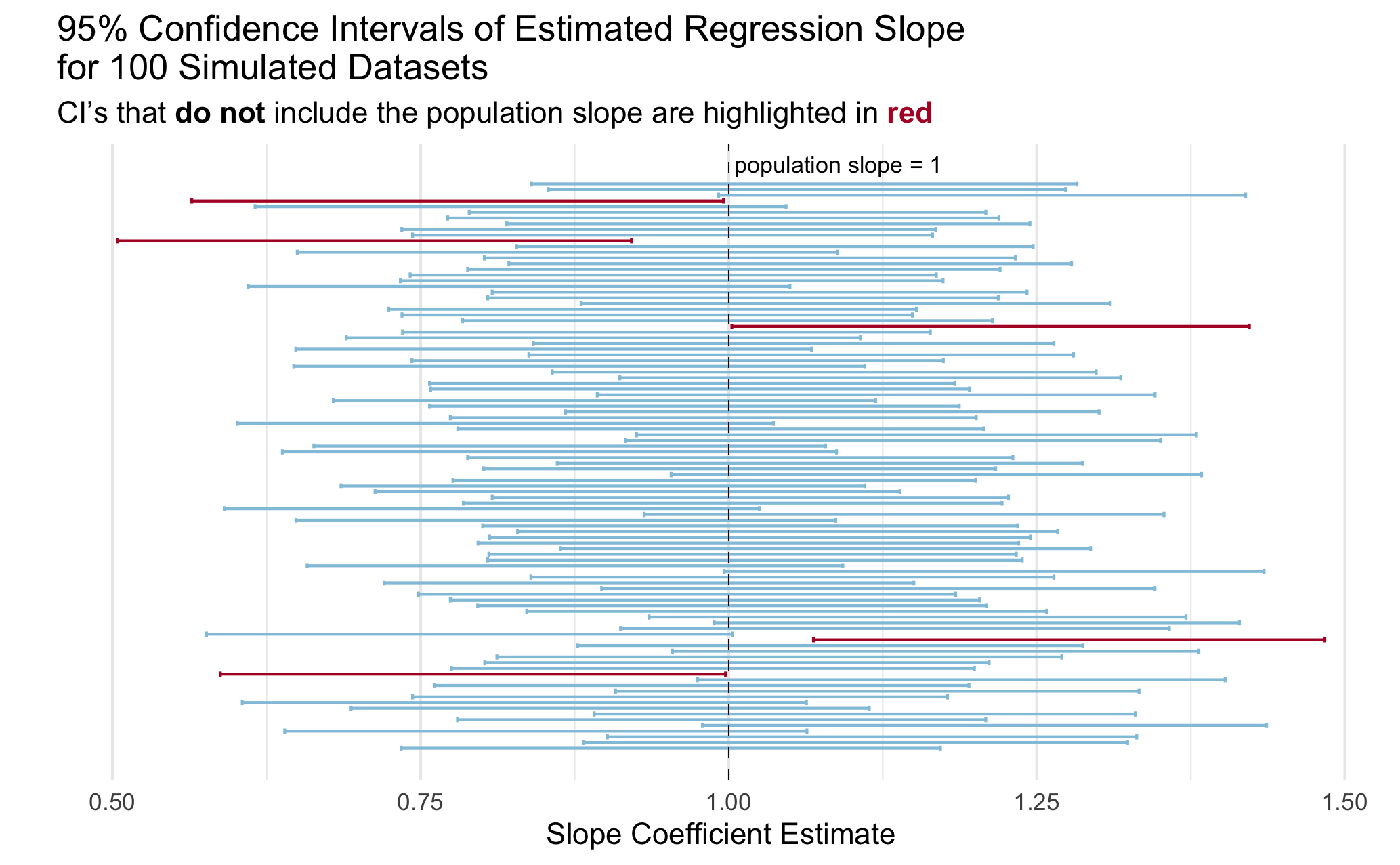
12. Create a visualization to illustrate the coverage rate.
You can create any visualization that effectively illustrates the concept. I included a plot below with my idea of an effective plot to illustrate the concept of coverage. Actually, a professor showed me a plot like this in undergrad and I have always remembered it!
Tip
You do not need to exactly copy the plot, even if you choose to do something like it. A couple of hints to get you started on making a plot like this one:
- Check out
geom_errorbar() - Check out
geom_vline()for the line indicating the true population slope - See this slide for code from Dr. Theobold to include colors in a title rather than a legend.
- I took a random sample of 100 simulations to make it easier to look at.
# Q12 code