# Data from Lab 2
surveys <- read_csv("../lab2/surveys.csv")
# Data from Lab 3
evals <- read_csv("../lab3/input/teacher_evals.csv") |>
rename(sex = gender)Lab 7: Searching for Efficiency
The Data
For this week’s lab, we will be revisiting questions from previous lab assignments, with the purpose of using user-written functions and functions from the map() family to iterate over certain tasks. To do this, we will need to load in the data from Lab 2 and Lab 3.
Edit the code below to read in the appropriate datsets that you should have saved from the previous labs!
Formatting Tables
In this lab, we will also practice making nice, report worthy, tables!
I would recommend you think of tables no different from the visualizations you’ve been making. We want all aspects of our tables to be clear to the reader, so the comparisons we want them to make are straightforward. You should be thinking about:
- Column headers
- Grouping headers
- Order of columns
- Order of rows
- Number of decimals included for numeric entries
- etc.
Tables are also a great avenue to display creativity! In fact, there is a yearly RStudio table contest, and here is a gallery of the award winning tables!
There are many packages for generating tables but I recommend either kable() function from the knitr package or gt() function from the gt package and their add-ons.
For simple tables
- the
kable()function from the knitr package for simple tables - the
gt()function from the gt package
For more sophisticated tables
- styling functions from the kableExtra package (e.g.,
kable_styling(),kable_classic()) - add-on functions from the gt package (e.g.,
cols_label(),tab_header(),fmt_percent())
Warning
Quarto doesn’t play nice with some options for formatting HTML tables in other packages.
To make sure that your tables render as expected, we need to specify html-table-processing: none in the YAML header. You will notice that I already included that in this lab.
I also recommend using the Source Editor for this lab.
Lab 2
First up, we’re going to revisit Question 2 from Lab 2. This question asked:
What are the data types of the variables in this dataset?
1. Using map_chr(), produce a table of the data type of each variable in the surveys dataset. Specifically, the table should have two columns var_name and type with a row for each variable and be displayed using kable().
Tip
You will want to check out the enframe() function to help with this task.
# Q1 code2. Format the table nicely! Think about the order of the rows to make the information easy to take in. Using either kable() and functions in the kableExtra package or gt() and functions from the gt package to make a table that includes a caption or header, and nice, bolded column names. Note that you should assign the column names when creating the table, not by renaming columns in the dataset itself because we hate variable names with spaces in them!
# Q2 codeLab 3
Now, were on to Lab 3 where we will revisit two questions.
In the original version of Lab 3, Question 4 asked you to:
Change data types in whichever way you see fit (e.g., is the instructor ID really a numeric data type?)
3. Using map_at() or map_if(), convert the course_id, weekday, academic_degree, time_of_day, and sex columns to factors. In other words, convert all character variables into factors. DO NOT PRINT OUT YOUR NEW DATA FRAME, just show the code. Hint: You will need to use bind_cols() to transform the list output back into a data frame.
# Q3 codeNext up, we’re going revisit Question 7 which asked:
What are the demographics of the instructors in this study? Investigate the variables
academic_degree,seniority, andsexand summarize your findings in ~3 complete sentences.
Many people created multiple tables of counts for each of these demographics, but in this exercise we are going to create one table with every demographic.
4. We are going to recreate the (mainly unformatted) table below using one pipeline. This is a lot to think through at once, so we are going to make it easier by breaking it down into a couple of steps.
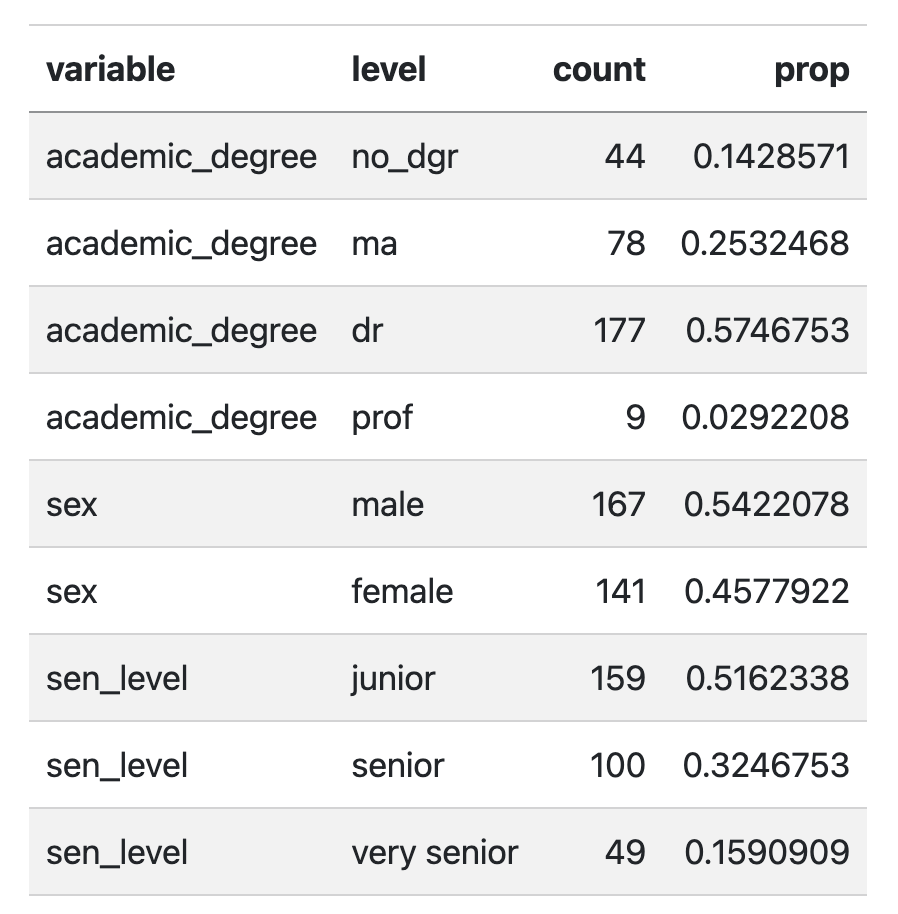
NoteBefore you move on.
Repeat the data cleaning steps that we did in Lab 3 before question 7 to recreate this exact table. And remember that we needed to first only keep one row per instructor.
I’m using the
sen_levelclassification from Lab 3
"junior"=seniorityis 4 or less (inclusive)"senior"=seniorityis between 4 and 8 (inclusive)"very senior"=seniorityis greater than 8.
# code for cleaning evals data for table
# (Should just be copied from lab 7.
# You can also see the solution on Canvas.)4a. Write a function called quick_table that takes a vector as the input and outputs a dataframe with three columns: level which takes the values of each level (or unique value) of the vector and count which shows the number of elements that have that level (unique value), and prop which show sthe proportion of elements that have that level.
For example, if the input to your function is this vector x:
x <- c("Ilya", "Shane", "Shane", "Scott", "Kip")The output should be the data frame (or tibble):
| level | count | prop |
|---|---|---|
| Ilya | 1 | 0.2 |
| Kip | 1 | 0.2 |
| Scott | 1 | 0.2 |
| Shane | 2 | 0.4 |
Tip
While we have seen how to do this for a colunn in a dataframe in dplyr using the count() function, when the input is a vector, the function you want to use is table().
It is easiest to start with creating a dataframe that has the level, and count columns and then calculate prop.
# Q4a codeKeep the following chunk of code to check that you created your quick_table() function and input validation correctly.
quick_table(evals$sex)Okay, now we are set-up to efficiently create that table for academic_degree, sex, and sen_level! Note that what we really want to do is apply this function to those three columns and then stack the result together… 🧐 sounds like a job for a map() function!
4b. Use your quick_table() function and map() to create the table above (Figure 1) in one pipeline.
Tip
The list_rbind() function and the names_to argument in that will be helpful!
Final tip (not required) - I used the following options in kable_styling() to output this table:
kable_styling(full_width = F,
bootstrap_options = "striped")# Q4b code5. Now turn that into a very nice table, like one of the examples below using kable() and kableExtra or gt.
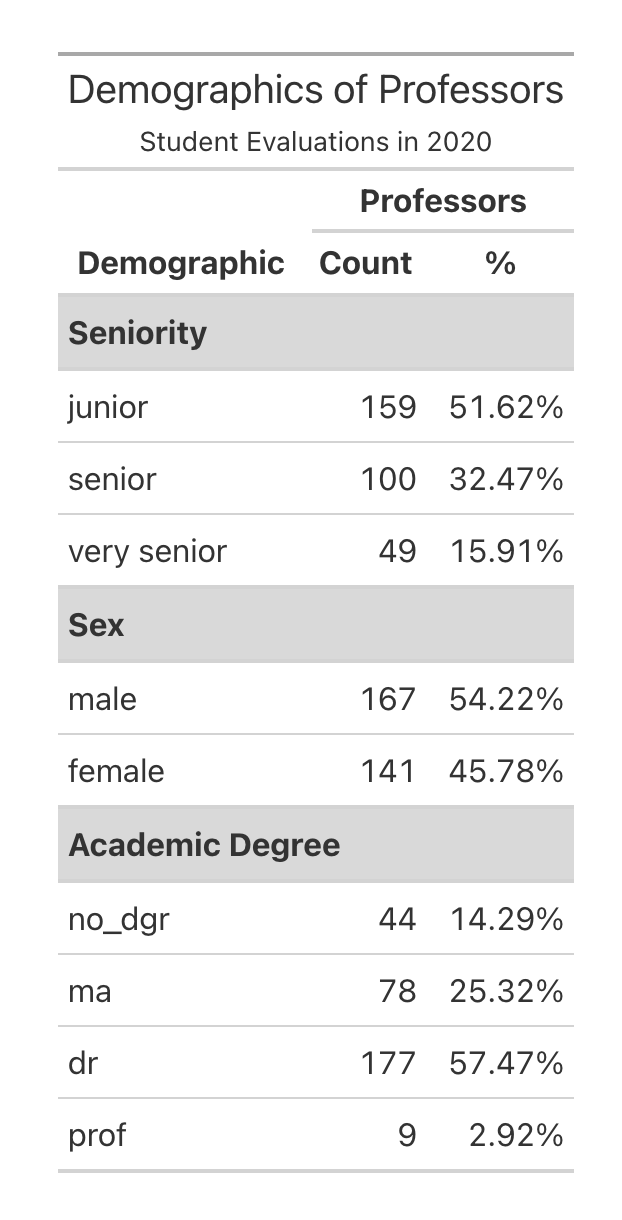
gt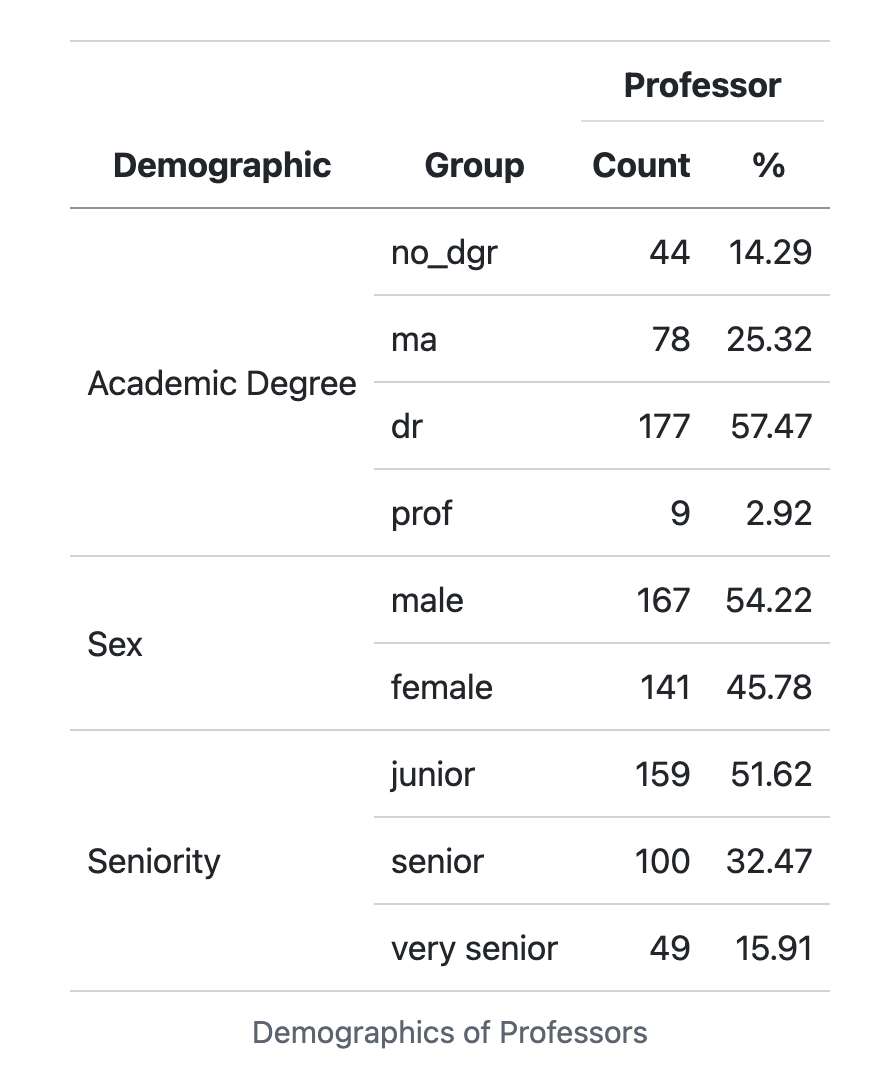
kableExtraYour table does not need to copy one of these exactly but it should include:
- Some way of clearly indicating the three variable types as row groups
- Giving nice column names
- Using a column header that spans the count and % columns
- Nicely formatting the % column
- Giving it a title or a caption
#Q5 codeLab 5
In lab 5 we got to solve a mystery using a bunch of different related data sets. Remember how we got the data?
This code chunk will read in all of the tables of data for you. Don’t modify or remove this!
This was also a mystery at the time! The code chunk given loaded an .Rdata file that included all of the data frames. However, your data may not always be saved in a nice .Rdata file Let’s write a more general function to read in lots of datasets ourselves!
6. Write a function whose only argument is a file path to a directly, that will read in all .csv files in that directory and return a list of the data frames.
Specifically your function should:
- Find the names of all .csv files in that directory (the
list.files()function will be helpful). - Use
map()to efficiently read all of the files into R and save the data frames in a list - Rename the elements of the list with the names of each file
- Return the list
Test your function on a directory that has at least two .csv files in it and show us that it works! DO NOT print full datasets. Show us that the output is a list and that the names of the list are file names. Your function should be able to handle if a directory includes files that aren’t only csv’s
# Q6 code
Tip
For example, if I have a directory data/ that has surveys.csv, teacher_evals.csv, and bCH_murder_data.Rdata in it, the function should return a list with two elements - the surveys and teacher_evals data frames. The names of the list elements should be "surveys" and "teacher_evals".
7. Add input validation to your function in Q6 that checks that the input is a single string (the format of a file path). Provide a helpful message to the user if it is not. Just edit your Q6 code to add this. Write code here to check if your input validation works (i.e. give input that should fail your validation and therefore show your nice message!).
# Q7 code - check input validation