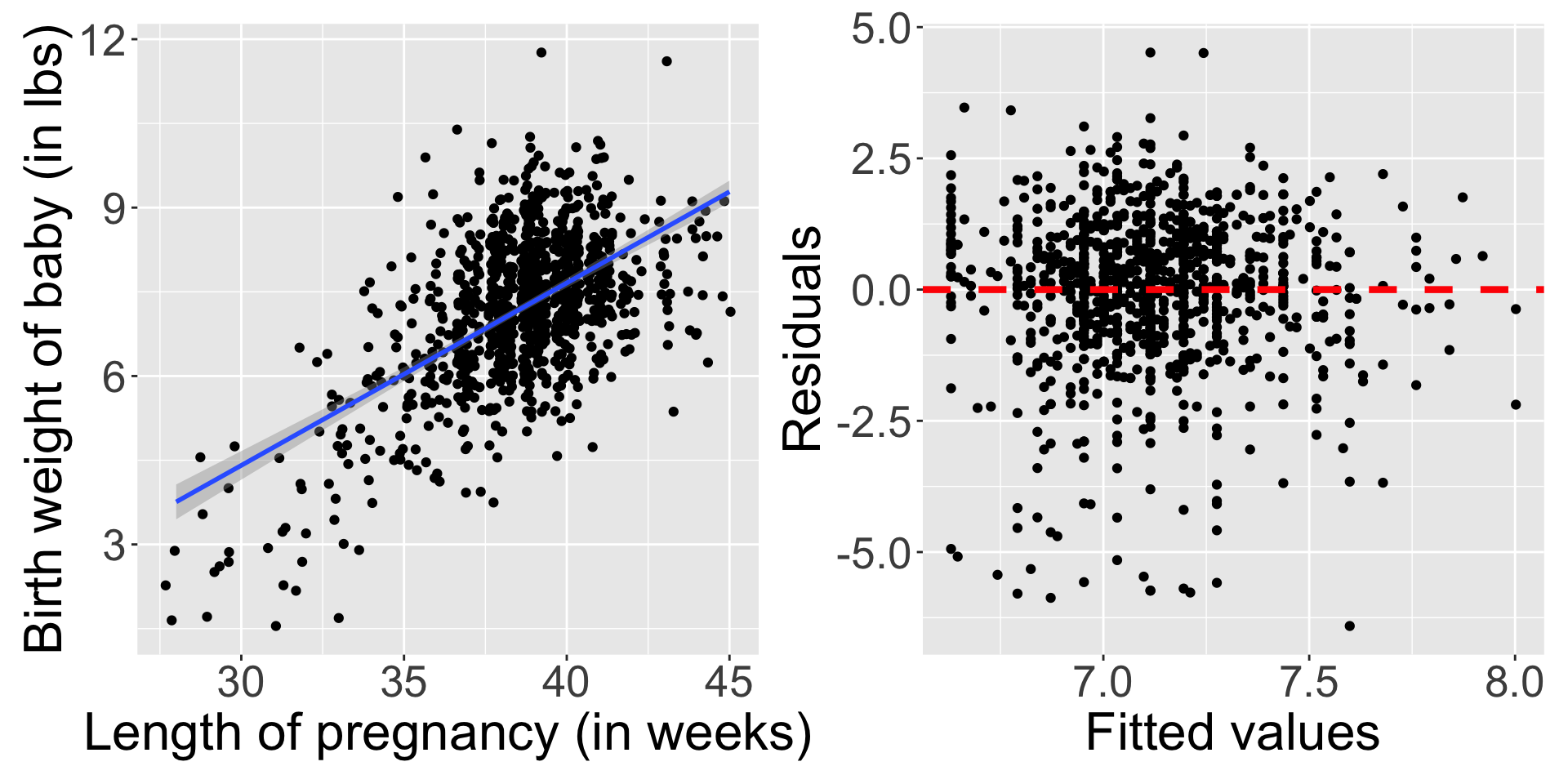
# A tibble: 6 × 13
premie fage mage mature weeks visits marital gained weight lowbirthweight
<fct> <int> <int> <fct> <int> <int> <fct> <int> <dbl> <fct>
1 full term NA 13 young… 39 10 not ma… 38 7.63 not low
2 full term NA 14 young… 42 15 not ma… 20 7.88 not low
3 full term 19 15 young… 37 11 not ma… 38 6.63 not low
4 full term 21 15 young… 41 6 not ma… 34 8 not low
5 full term NA 15 young… 39 9 not ma… 27 6.38 not low
6 full term NA 15 young… 38 19 not ma… 22 5.38 low
# ℹ 3 more variables: gender <fct>, habit <fct>, whitemom <fct>
# A tibble: 6 × 5
premie habit weight gained pred_weight
<fct> <fct> <dbl> <int> <dbl>
1 full term nonsmoker 7.63 38 7.55
2 full term nonsmoker 7.88 20 7.43
3 full term nonsmoker 6.63 38 7.55
4 full term nonsmoker 8 34 7.53
5 full term nonsmoker 6.38 27 7.48
6 full term nonsmoker 5.38 22 7.44